7.1k Star 开源 OCR 与深度文档理解 RAG 引擎 RAGFlow 的革新与商业集成
在人工智能与信息处理技术飞速发展的今天,如何从海量、非结构化的文档数据中精准、高效地提取并利用知识,已成为企业智能化转型的核心挑战之一。一个名为 RAGFlow 的开源项目在 GitHub 上引起了广泛关注,它以超过 7.1k Star 的成绩,彰显了社区对其技术价值与应用潜力的高度认可。RAGFlow 不仅仅是一个简单的检索增强生成(RAG)框架,它深度融合了尖端的 OCR(光学字符识别) 技术与 深度文档理解 能力,致力于打造一个能够“读懂”复杂文档的智能引擎,并通过严谨的“大海捞针”测试、有效的幻觉抑制机制以及便捷的服务化 API,为将其无缝 集成进业务系统 和提供专业的 计算机系统集成服务 铺平了道路。
一、 核心能力:超越文本的深度文档理解
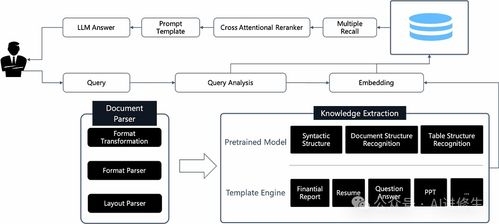
传统 RAG 方案大多以纯文本为处理对象,对于包含丰富版面信息(如表格、图表、公式、多栏排版)的扫描件、PDF、图像等文档往往力不从心。RAGFlow 的创新之处在于,它将强大的 OCR 引擎作为信息提取的“眼睛”,首先将图像或版式文档中的文字、表格结构、乃至数学公式准确识别并转化为结构化数据。更重要的是,其内置的深度文档理解模型能够解析文档的逻辑结构,理解不同元素(如标题、段落、图表说明、表格数据)之间的语义关联,从而构建出远超纯文本序列的、富含语义和结构信息的文档知识表示。这使得 RAGFlow 能够真正“理解”一份技术报告、一份财务报表或一份研究论文的内容精髓。
二、 精准可靠:通过“大海捞针”测试与降低幻觉
RAG 系统的核心痛点在于检索的准确性与生成答案的可靠性。“大海捞针”测试是一种经典的评估方法,旨在检验系统能否从庞大的知识库中精准定位并提取出极其细微、关键的信息片段。RAGFlow 针对此进行了深度优化,通过多级索引、混合检索(结合语义向量检索与关键词检索)以及基于文档结构的精细化分块策略,显著提升了“捞针”的成功率与速度。
“幻觉”问题——即模型生成看似合理但实际与提供知识不符的内容——是阻碍 RAG 系统投入生产环境的主要障碍。RAGFlow 通过多重机制对抗幻觉:其检索阶段的高精度为生成阶段奠定了可靠的事实基础;它在生成过程中强化了对检索出原文片段的引用与忠实度,鼓励模型“循证作答”;系统可配置后处理校验环节,进一步确保输出内容的真实性与准确性。这种对精准与可靠性的极致追求,是 RAGFlow 能够胜任企业级严肃应用的关键。
三、 开箱即用:服务化 API 与无缝业务集成
技术的最终价值在于落地。RAGFlow 并非一个仅供研究的算法库,而是一个设计完善、面向生产环境的系统。它提供了清晰、稳定的 服务化 API(应用程序编程接口)。这意味着开发人员无需深入其复杂的内部架构,只需通过简单的 HTTP 调用,即可将文档解析、知识库构建、智能问答等核心能力快速集成到现有的业务流程、办公系统、客户服务门户或内部知识管理平台中。这种低耦合、高内聚的设计极大降低了集成门槛,加速了AI能力的业务化进程。
四、 面向企业:提供计算机系统集成服务
基于其强大的技术内核和友好的集成接口,RAGFlow 能够作为核心引擎,支撑起更广泛的 计算机系统集成服务。对于有复杂需求的企业客户,技术团队可以以 RAGFlow 为基础,定制开发符合特定行业场景(如法律文书分析、医疗报告解读、金融研报处理、工程图纸管理)的垂直解决方案。这包括但不限于:与企业现有数据中台的对接、私有化部署保障数据安全、针对专有领域知识的模型微调、设计复杂的多轮对话与工作流等。RAGFlow 的开源开放性为这类深度集成与服务提供了坚实的基础和灵活的定制空间。
**
总而言之,RAGFlow 凭借其 7.1k Star 的开源热度,标志着社区对下一代智能文档处理方向的共同期待。它通过 OCR 与深度文档理解 的结合,突破了传统 RAG 的局限;以 “大海捞针”级的检索精度 和 有效的幻觉抑制 确保了系统的可靠性;最终通过 服务化 API 和支撑 计算机系统集成服务** 的潜力,架起了从尖端技术到实际业务价值的桥梁。对于任何希望从文档海洋中挖掘知识金矿的组织而言,RAGFlow 无疑是一个值得密切关注和深入探索的强大工具。
如若转载,请注明出处:http://www.aiweiouto.com/product/78.html
更新时间:2026-06-19 08:53:17